在介紹了這麼多演算,究竟要如何選擇最適合的演算法呢?接下來將會講解幾種選擇適合演算法的方法以及一些重要原則來做為收尾。
以下將會介紹幾種衡量演算法準確度的重要指標。
混淆矩陣(Confusion Matrix)
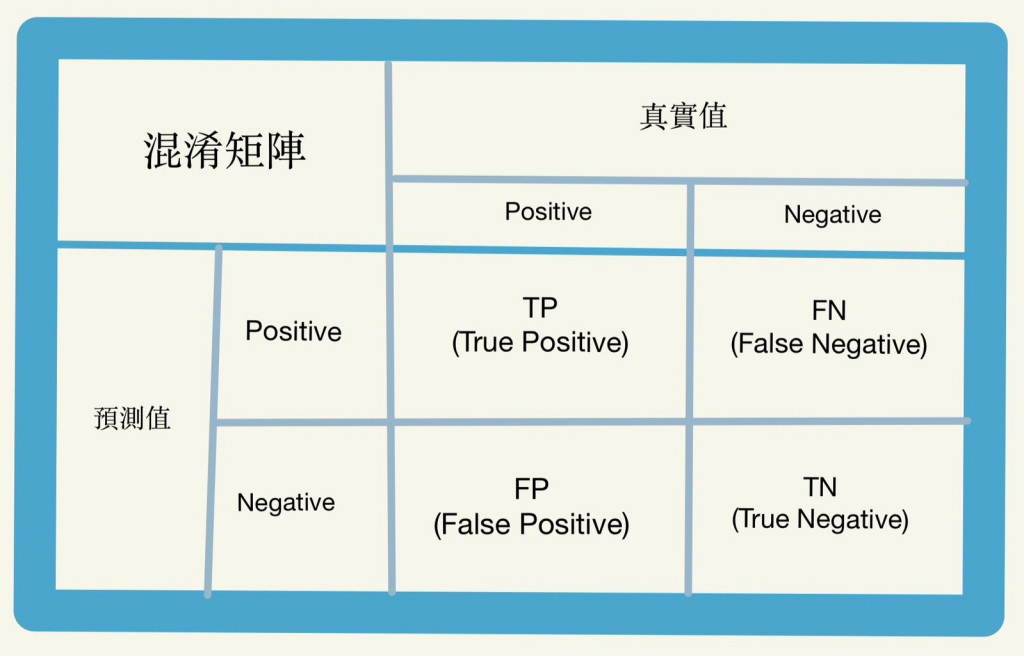
混淆矩陣是一種透過演算法所預測的分類與實際分類來比較顯示出機器預測的正確與錯誤程度的一種矩形工具。
- TP(True Positive)表示實際的結果與預測的結果一致,是正確預測。
- TN(True Negative)表示實際的結果與預測的結果一致,是正確預測。
- FP(False Positive)表示預測質陽性而實際結果正為陰性,也就是所謂的錯殺率。
- FN(False Negative)表示預測結果為陰性而實際為陽性,也就是所謂的漏網之魚。
準確性(Accuracy)
以下為準確率之公式。
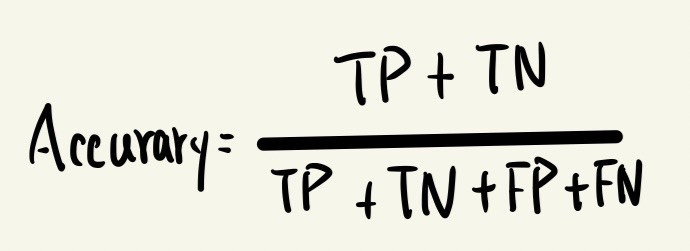
指機器正確預測的選項占百分比的多少。例如100個事件中,TP為25個,TN為55個,則準確率為(25+55)/100=0.8。
精確度(Precision)
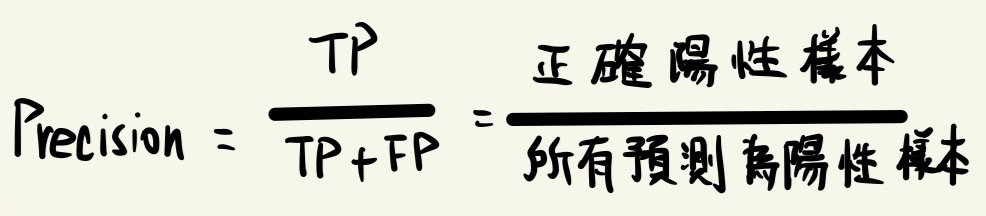
簡單來說,就是你抓到的所有人中有幾個是真正的罪犯,也就是錯殺率大小的概念,爾想當然是精確度越大錯殺率便為越小。
召回率(Recall)

也就是所謂的漏網之魚比例,這對像是癌症等等較為嚴肅的判斷中,召回率若是太高將會造成無法挽回的後果,因此這時候會建議採去寧可錯殺也不要去放過任何一條漏網之魚。
F1值

F1主要為同時考慮準確度與召回率,求取一個平衡錯殺率與漏網率整合性的正確指標,並利用此指標來表示AI模式的整體效能。
演算法錯誤模式的衡量
偏差與方差
偏差(Bias)表示不正確的程度,即為預測值與真實質之間的差距,偏差越高表示偏移真實值的程度越大;方差(Variance)表示不穩定的程度,即為預測值的變化範圍與離散程度,方差越大數據的分佈越分散。
過度擬合與擬合不足
- 過度擬合(Overfitting):指一個特殊的模式其指能精確、緊密的匹配「訓練樣本」,以至於訓練完後,對於實際真正的樣本無法找到一個通用的法則來偵測這些外部的樣本而產生了許多的預測錯誤,導致準確度降低的情況。簡單來說,就是在機器一直在一個虛擬的環境進行演練,而當真正來到現實時,它會因為太多沒有處理過的情況而造成不知道該如何處理。
所以開發者必須利用各種交叉驗證,不斷的變化訓練的樣本與測試的樣本,以及增加樣本的多樣性與數量、降低模式複雜度等等來改正與預防。
- 擬合不足(Underfitting):與過度擬合相反,使用了過於簡單的模式來預測太複雜的真實情況,而造成錯誤率極高,此時則應該使用更複雜的模式來改善擬合不足的問題。
參考資料
人工智慧-概念應用與管理 林東清著


 iThome鐵人賽
iThome鐵人賽